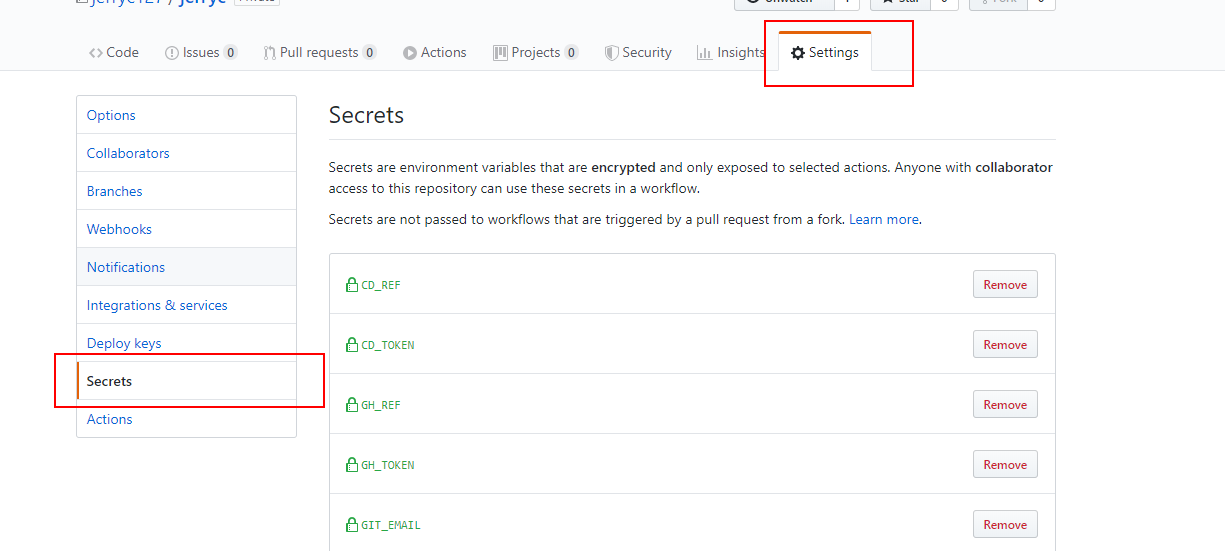
CrazyWonghttps://www.gravatar.com/avatar/7d88658473effdd6b068e181b9636878熱衷學習,熱衷生活2024-02-22T09:15:04.299Zhttps://blog.crazywong.com/Jerrymy@crazywong.comHexo🎧 Anson Seabra - Keep Your Head Up Princesshttps://blog.crazywong.com/posts/anson-seabra-keep-your-head-up-princess/2021-11-28T06:27:36.000Z2024-02-22T09:15:04.299Z
My Princess 別低頭 皇冠會掉
When she was younger she would pretend 在她小的時候 她會假裝
That her bedroom was a castle she was fairest in the land 她的卧室是一座城堡 她是這個國度裏最美麗的女孩
And she got older and it all changed 她漸漸長大 一切都物是人非
There was no time for make believe and all the magic slipped away 沒有時間徜徉在幻想裏 所有魔力悄然流逝
Until the light in her eyes it was all but gone 直到她眼中的光芒消失殆盡
‘Cause all the dreams that she had turned out to be wrong 因為她擁有的所有夢想不過都是幼稚可笑的錯誤
So keep your head up princess ‘fore your crown falls 昂首闊步 別讓頭頂的王冠掉落
Know these voices in your head will be your downfall 縈繞腦海裏那些質疑聲音 只會讓你的心不堪一擊
I know it gets so hard but you don’t got far to go 我知道這萬分艱難 而前路並非遙不可及
Yeah keep your head up princess it’s a long road 昂首闊步 這是條漫長的道路
And the path leads right to where they won’t go 是他們都不會選擇去走的一條路
I know it hurts right now but I know you’ll make it home 路程艱辛 但我相信你定會到達終點 載譽歸來
So keep your head up 堅定腳步
Yeah keep your head up 不忘初心
And now she’s grown up works at a bar 現在她長大成人 在酒吧找到一份工作
She traded makeshift gowns for serving rounds from sunrise ‘til it’s dark 她穿着簡單質樸的衣服 披星戴月地賣力工作
And all her friends got someone to hold 她所有的朋友都已找到歸宿
And she’s got no one else still not prepared to make it on her own 可她孑然一身 依然沒有準備好自力更生
And now the light in her eyes it’s now all but gone 現在她眼中的光芒消失殆盡
‘Cause all the dreams that she had turned out to be wrong 因為她擁有的所有夢想不過都是幼稚可笑的錯誤
So keep your head up princess ‘fore your crown falls 昂首闊步 別讓頭頂的王冠掉落
Know these voices in your head will be your downfall 縈繞腦海裏那些質疑聲音 只會讓你的心不堪一擊
I know it gets so hard but you don’t got far to go 我知道這萬分艱難 而前路並非遙不可及
Yeah keep your head up princess it’s a long road 昂首闊步 這是條漫長的道路
And the path leads right to where they won’t go 是他們都不會選擇去走的一條路
I know it hurts right now but I know you’ll make it home 路程艱辛 但我相信你定會到達終點 載譽歸來
So keep your head up 堅定腳步
Yeah keep your head up 不忘初心
One day you’ll find your way back to the start 總有一天 你會找到方向 回到原點
One day you’ll live in your dreams 總有一天 你會沉浸在你的美夢裏
One day you’ll wake up and girl you’ll be a queen 總有一天 你會醒來 你將成為無與倫比的女王
So keep your head up princess ‘fore your crown falls 昂首闊步 別讓頭頂的王冠掉落
Know these voices in your head will be your downfall 縈繞腦海裏那些質疑聲音 只會讓你的心不堪一擊
I know it gets so hard but you don’t got far to go 我知道這萬分艱難 而前路並非遙不可及
Yeah keep your head up princess it’s a long road 昂首闊步 這是條漫長的道路
And the path leads right to where they won’t go 是他們都不會選擇去走的一條路
I know it hurts right now but I know you’ll make it home 路程艱辛 但我相信你定會到達終點 載譽歸來
So keep your head up 堅定腳步
Yeah keep your head up 不忘初心
]]>Anson Seabra - Keep Your Head Up Princess,很不錯的一首歌。是的,我又更換了域名https://blog.crazywong.com/posts/change-domain-again/2021-11-10T11:25:24.000Z2024-02-22T09:15:04.303Z年初才把域名換到了 immyw.com, 還沒到一年,又把域名換到了 crazywong.com。
之前爲了安全起見,給 Godaddy 開了兩步認證,選擇了 Microsoft Authenticator 儲存驗證。然後倒霉的事情來了,一次不小心的操作,把 Microsoft Authenticator 給刪了,本想著有備份,重新下載軟件再恢復就行。結果可想而知,備份丟了。無奈之下,只能一個個去申訴回來。
var colors = newArray(); var colors = Array(); var colors = newArray(20); // 創建長度為20的數組 var colors = newArray("red","blue","green") // 創建包含3個字符串的數組
使用數組字面量表示法
1 2 3 4
var color = ['red','blue'] var color = [] // 空數組 var color = [1,2,] // ie8及之前的版本,會是一個包含1,2,undefined 的數組(長度3),其它的瀏覽器會生成一個包含1,2的數組(長度2) var color = [,,,,,] // ie8及之前會創建包含6項的數組,其它的瀏覽器可能會創建包含5項的數組。每一項都是 undefined
讀取和設置數組的值
1 2 3 4
var color = ['red','blue','green'] color[0] // red 獲取第一項 color[1] = 'black'// 修改第二項 color[3] = 'yellow'// 新增第四項
2018年6月,心血來潮去買了一個域名。當時看到一個 me 後綴,感覺挺適合做個人博客的。本來想買 jerry.me , 很顯然這麼好的域名早就被人註冊了。無奈之下,退而一步選擇了 jerryc。 jerryc 也是我很多賬號的名字(畢竟 jerry 註冊不到)。之後一直有人問我,是不是彈吉他的那位。我就納悶,我也不會彈吉他。去 Google 了之後才發現
原來 jerryc 是一個有名的吉他手啊,怪不得有人問我是不是他本人。
這也帶來另一個煩惱,就是搜索首頁都是他的內容,我自己的網站要到第2,3頁才顯示。畢竟網站的流量不高,那排在首頁的機會就越來越小的。加上 me 域名還是太小眾了,選擇 com 域名還是最好的選擇。
好的 com 域名基本已經被註冊掉了,曾聯繫過一個賣家詢問域名出售,然而報價太高,只能望而卻步。在 Godaddy 上試了很多域名,最終選擇了 immyw 這個域名。不得不説 com 域名比 me 域名便宜太多。
let key = 'name' let user = { name: 'leo', age: 18, } // ok user[key] // "leo" user[key] = 'pingan'
// error user.key// undefined
計算屬性
創建對象時,可以在對象字面量中使用方括號,即 「計算屬性」 :
1 2 3 4 5 6 7 8
let key = 'name' let inputKey = prompt('請輸入key', 'age') let user = { [key]: 'leo', [inputKey]: 18, } // 當用户在 prompt 上輸入 "age" 時,user 變成下面樣子: // {name: "leo", age: 18}
當然,計算屬性也可以是表達式:
1 2 3 4 5
let key = 'name' let user = { ['my_' + key]: 'leo', } user['my_' + key] // "leo"
屬性名簡寫
實際開發中,可以將相同的屬性名和屬性值簡寫成更短的語法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// 原本書寫方式 let getUser = function (name, age) { // ... return { name: name, age: age, } }
// 簡寫方式 let getUser = function (name, age) { // ... return { name, age, } }
也可以混用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// 原本書寫方式 let getUser = function (name, age) { // ... return { name: name, age: 18, } }
// 簡寫方式 let getUser = function (name, age) { // ... return { name, age: 18, } }
對象屬性存在性檢測
使用 in 關鍵字
該方法可以判斷「對象的自有屬性和繼承來的屬性」是否存在。
1 2 3 4
let user = { name: 'leo' } 'name'in user //true,自有屬性存在 'age'in user //false "toString"in user; //true,是一個繼承屬性
使用對象的 hasOwnProperty() 方法。
該方法只能判斷「自有屬性」是否存在,對於「繼承屬性」會返回 false 。
1 2 3 4
let user = {name: "leo"}; user.hasOwnProperty("name"); //true,自有屬性中有 name user.hasOwnProperty("age"); //false,自有屬性中不存在 age user.hasOwnProperty("toString"); //false,這是一個繼承屬性,但不是自有屬性
6.3 用 undefined 判斷
該方法可以判斷對象的「自有屬性和繼承屬性」。
1 2 3 4
let user = {name: "leo"}; user.name !== undefined; // true user.age !== undefined; // false user.toString !== undefined// true
該方法存在一個問題,如果屬性的值就是 undefined 的話,該方法不能返回想要的結果:
1 2 3 4
let user = {name: undefined}; user.name !== undefined; // false,屬性存在,但值是undefined user.age !== undefined; // false user.toString !== undefined; // true
6.4 在條件語句中直接判斷
1 2 3 4 5
let user = {} if (user.name) user.name = 'pingan' //如果 name 是 undefine, null, false, " ", 0 或 NaN,它將保持不變
user // {}
對象循環遍歷
當我們需要遍歷對象中每一個屬性,可以使用 for...in 語句來實現
for…in 循環
for...in 語句以任意順序遍歷一個對象的除 Symbol 以外的可枚舉屬性。「注意」 :for...in 不應該應用在一個數組,其中索引順序很重要。
1 2 3 4 5 6 7 8 9 10
let user = { name: 'leo', age: 18, }
for (let k in user) { console.log(k, user[k]) } // name leo // age 18
let obj = { name: 'leo', } functionfun(name) { if (name == obj.name) { console.log('hello') } } fun(obj.name) // 'hello'
使用Symbol消除強耦合,使得不需關係具體的值:
1 2 3 4 5 6 7 8 9
let obj = { name: Symbol(), } functionfun(name) { if (name == obj.name) { console.log('hello') } } fun(obj.name) // 'hello'
屬性名遍歷
Symbol 作為屬性名遍歷,不出現在for...in、for...of循環,也不被Object.keys()、Object.getOwnPropertyNames()、JSON.stringify()返回。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
let leo = Symbol('leo'), robin = Symbol('robin') let user = { [leo]: '18', [robin]: '28', } for (let k ofObject.values(user)) { console.log(k) } // 無輸出
let user = {} let leo = Symbol('leo') Object.defineProperty(user, leo, { value: 'hi' }) for (let k in user) { console.log(k) // 無輸出 } Object.getOwnPropertyNames(user) // [] Object.getOwnPropertySymbols(user) // [Symbol(leo)]
Object.getOwnPropertySymbols方法返回一個數組,包含當前對象所有用做屬性名的 Symbol 值。
1 2 3 4 5 6 7
let user = {} let leo = Symbol('leo') let pingan = Symbol('pingan') user[leo] = 'hi leo' user[pingan] = 'hi pingan' let obj = Object.getOwnPropertySymbols(user) obj // [Symbol(leo), Symbol(pingan)]
另外可以使用Reflect.ownKeys方法可以返回所有類型的鍵名,包括常規鍵名和 Symbol 鍵名。
1 2 3 4 5 6
let user = { [Symbol('leo')]: 1, age: 2, address: 3, } Reflect.ownKeys(user) // ['age', 'address',Symbol('leo')]
由於 Symbol 值作為名稱的屬性不被常規方法遍歷獲取,因此常用於定義對象的一些非私有,且內部使用的方法。
Symbol.for()、Symbol.keyFor()
Symbol.for()
「用於重複使用一個 Symbol 值」,接收一個「字符串」作為參數,若存在用此參數作為名稱的 Symbol 值,返回這個 Symbol,否則新建並返回以這個參數為名稱的 Symbol 值。
1 2 3
let leo = Symbol.for('leo') let pingan = Symbol.for('pingan') leo === pingan // true
P 是一個類,new P() 會返回一個實例,該實例的Symbol.hasInstance方法,會在進行instanceof運算時自動調用,判斷左側的運算子是否為Array的實例。
Symbol.isConcatSpreadable
值為布爾值,表示該對象用於Array.prototype.concat()時,是否可以展開。
1 2 3 4 5 6 7 8
let a = ['aa', 'bb'] ;['cc', 'dd'].concat(a, 'ee') // ['cc', 'dd', 'aa', 'bb', 'ee'] a[Symbol.isConcatSpreadable] // undefined let b = ['aa', 'bb'] b[Symbol.isConcatSpreadable] = false ;['cc', 'dd'].concat(b, 'ee') // ['cc', 'dd',[ 'aa', 'bb'], 'ee']
Symbol.species
指向一個構造函數,在創建衍生對象時會使用,使用時需要用get取值器。
1 2 3 4 5
classPextendsArray { static get [Symbol.species]() { returnthis } }
解決下面問題:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// 問題: b應該是 Array 的實例,實際上是 P 的實例 classPextendsArray {} let a = newP(1, 2, 3) let b = a.map((x) => x) b instanceofArray// true b instanceof P // true // 解決: 通過使用 Symbol.species classPextendsArray { static get [Symbol.species]() { returnArray } } let a = newP() let b = a.map((x) => x) b instanceof P // false b instanceofArray// true
classP { *[Symbol.interator]() { let i = 0 while (this[i] !== undefined) { yieldthis[i] ++i } } } let a = newP() a[0] = 1 a[1] = 2 for (let k of a) { console.log(k) }
當 if 語句當條件表達式,會將表達式轉換為布爾值,當為 truthy 時執行裏面代碼。轉換規則如:
數字 0、空字符串 ""、null、undefined 和 NaN 都會被轉換成 false。因為他們被稱為 “falsy” 值。
其他值被轉換為 true,所以它們被稱為 “truthy”。
三元運算符
「條件(三元)運算符」是 JavaScript 僅有的使用三個操作數的運算符。一個條件後面會跟一個問號(?),如果條件為 truthy ,則問號後面的表達式 A 將會執行;表達式 A 後面跟着一個冒號(:),如果條件為 falsy ,則冒號後面的表達式 B 將會執行。本運算符經常作為 [if](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/if...else) 語句的簡捷形式來使用。語法:
functionA(){ console.log('called A'); returnfalse; } functionB(){ console.log('called B'); returntrue; } console.log( A() && B() ); // logs "called A" due to the function call, // then logs false (which is the resulting value of the operator) console.log( B() || A() ); // logs "called B" due to the function call, // then logs true (which is the resulting value of the operator)
注意
與運算 && 的優先級比或運算 || 要高。所以代碼 a && b || c && d 完全跟 && 表達式加了括號一樣:(a && b) || (c && d)。
所謂 case 分組,就是與多個 case 分支共享同一段代碼,如下面例子中 case 1 和 case 2:
1 2 3 4 5 6 7 8 9 10 11 12 13
let a = 2; switch (a) { case1: // (*) 下面這兩個 case 被分在一組 case2: console.log('case is 1 or 2!'); break; case3: console.log('case is 3!'); break; default: console.log('The result is default.'); } // 'case is 1 or 2!'
注意點
「expression 表達式的值與 case 值的比較是嚴格相等:」
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
functionf(n){ let a ; switch(n){ case1: a = 'number'; break; case'1': a = 'string'; break; default: a = 'default'; break; } console.log(a) } f(1); // number f('1'); // string
「如果沒有 break,程序將不經過任何檢查就會繼續執行下一個 case:」
1 2 3 4 5 6 7 8 9 10 11 12 13 14
let a = 2 + 2; switch (a) { case3: console.log( 'Too small' ); case4: console.log( 'Exactly!' ); case5: console.log( 'Too big' ); default: console.log( "I don't know such values" ); } // Exactly! // Too big // I don't know such values
let fun = function(){ console.log(arguments); console.log(arguments.length); } fun('leo'); // Arguments ["leo", callee: ƒ, Symbol(Symbol.iterator): ƒ] // 1
以一個實際示例介紹,實現將任意數量參數連接成一個字符串,並輸出的函數:
1 2 3 4 5 6 7 8
let argumentConcat = function(separator){ let result = '', i; for(i = 1; i < arguments.length; i ++){ result += arguments[i] + separator; } return result; } argumentConcat(',', 'leo', 'pingan'); //"leo,pingan,"
函數返回值
在函數任意位置,指定 return 指令來停止函數的執行,並返回函數指定的返回值。
1 2 3 4 5
let sum = function(a, b){ return a + b; }; let res = sum(1, 2); console.log(res); // 3
// 函數表達式 let fun = function(){}; // 函數聲明 function fun(){}
創建時機差異
函數表達式會在代碼執行到達時被創建,並且僅從那一刻可用。而函數聲明被定義之前,它就可以被調用。
1 2 3 4 5 6
// 函數表達式 fun(); // Uncaught ReferenceError: fun is not defined let fun = function(){console.log('leo')}; // 函數聲明 fun(); // "leo" functionfun(){console.log('leo')};
// 有1個參數 letf = v => v; // 等同於 let f = function (v){return v}; // 有多個參數 letf = (v, i) => {return v + i}; // 等同於 let f = function (v, i){return v + i}; // 沒參數 letf = () => 1; // 等同於 let f = function (){return1}; let arr = [1,2,3,4]; arr.map(ele => ele + 1); // [2, 3, 4, 5]
注意點
箭頭函數不存在this;
箭頭函數不能當做「構造函數」,即不能用new實例化;
箭頭函數不存在arguments對象,即不能使用,可以使用rest參數代替;
箭頭函數不能使用yield命令,即不能用作 Generator 函數。一個簡單的例子:
1 2 3 4 5 6 7
functionPerson(){ this.age = 0; setInterval(() => { this.age++; }, 1000); } var p = newPerson(); // 定時器一直在執行 p的值一直變化
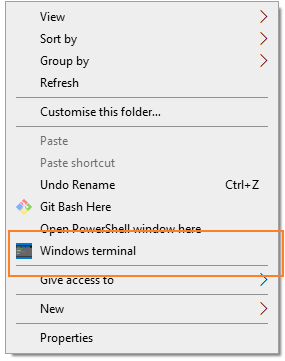
Windows上有很多命令行程序,例如CMD和PowerShell。微軟在Build 2019上推出了一款面向Windows10的命令行程序,這款程序集合了Windows上的PowerShell、CMD以及Windows Subsystem for Linux於一身,解決了不少惹人吐槽的毛病,甚至被稱為Windows下命令體驗的救世主。而我早在Preview版發佈時,就已經下載使用,現在也是我主要使用的命令行工具。然而畢竟現在還是體驗版的關係,所以並沒有集成在右鍵菜單上。在搜索了許久之後,終於在Github上找到了安裝方法。
軟件安裝
Windows Terminal 現在還是 Preview 狀態,我們可以在 Microsoft Store 上下載安裝。當然有能力的人,可以下載Github的代碼自己編譯。
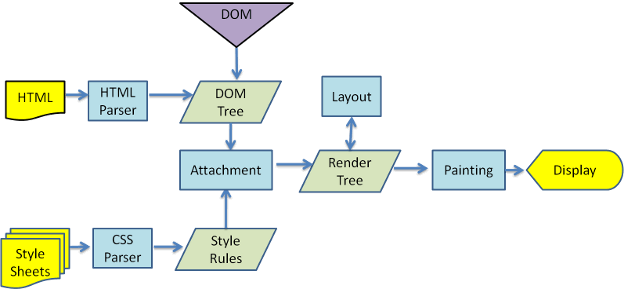
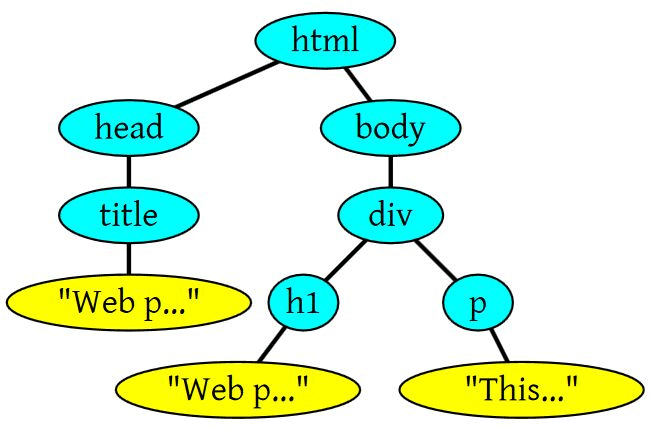
<html> <head> <title>Web page parsing</title> </head> <body> <div> <h1>Web page parsing</h1> <p>This is an example Web page.</p> </div> </body> </html>
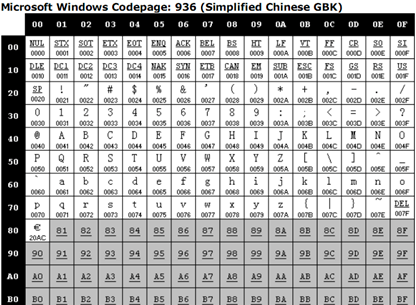
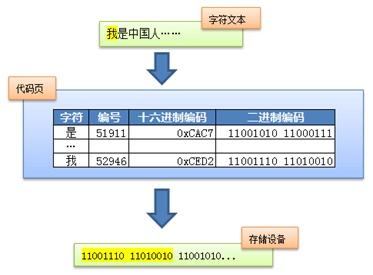
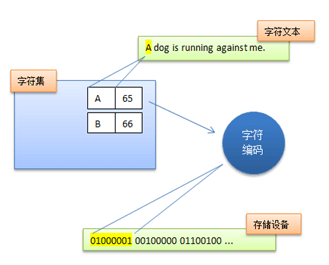
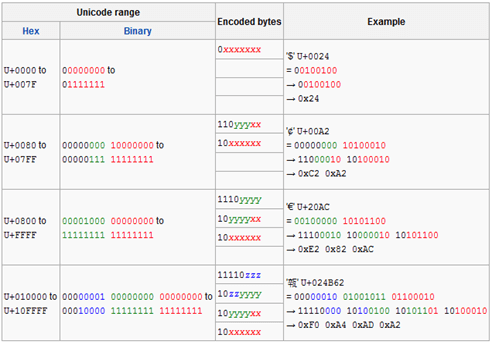
上面我們提到的字符集都是基於單字節編碼,也就是説,一個字節翻譯成一個字符。這對於拉丁語系國家來説可能沒有什麼問題,因為他們通過擴展第8個比特,就可以得到256個字符了,足夠用了。但是對於亞洲國家來説,256個字符是遠遠不夠用的。因此這些國家的人為了用上電腦,又要保持和ASCII字符集的兼容,就發明了多字節編碼方式,相應的字符集就稱為多字節字符集。例如中國使用的就是雙字節字符集編碼(DBCS,Double Byte Character Set)。
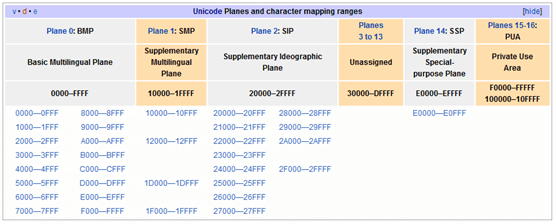
正在這時,大天使加百列及時出現了——一個叫 ISO(國際標誰化組織)的國際組織決定着手解決這個問題。他們採用的方法很簡單:廢了所有的地區性編碼方案,重新搞一個包括了地球上所有文化、所有字母和符號 的編碼!他們打算叫它”Universal Multiple-Octet Coded Character Set”,簡稱 UCS, 俗稱 “unicode“。
unicode開始制訂時,計算機的存儲器容量極大地發展了,空間再也不成為問題了。於是 ISO 就直接規定必須用兩個字節,也就是16位來統一表示所有的字符,對於ASCII裏的那些”半角”字符,unicode包持其原編碼不變,只是將其長度由原來的8位擴展為16位,而其他文化和語言的字符則全部重新統一編碼。由於”半角”英文符號只需要用到低8位,所以其高8位永遠是0,因此這種大氣的方案在保存英文文本時會多浪費一倍的空間。
unicode在很長一段時間內無法推廣,直到互聯網的出現,為解決unicode如何在網絡上傳輸的問題,於是面向傳輸的眾多 UTF(UCS Transfer Format)標準出現了,顧名思義,UTF-8就是每次8個位傳輸數據,而UTF-16就是每次16個位。UTF-8就是在互聯網上使用最廣的一種unicode的實現方式,這是為傳輸而設計的編碼,並使編碼無國界,這樣就可以顯示全世界上所有文化的字符了。UTF-8最大的一個特點,就是它是一種變長的編碼方式。它可以使用1~4個字節表示一個符號,根據不同的符號而變化字節長度,當字符在ASCII碼的範圍時,就用一個字節表示,保留了ASCII字符一個字節的編碼做為它的一部分,注意的是unicode一箇中文字符佔2個字節,而UTF-8一箇中文字符佔3個字節)。從unicode到utf-8並不是直接的對應,而是要過一些算法和規則來轉換。
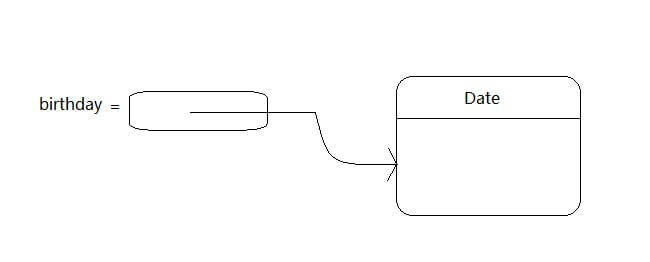
構造器的名字應與類名相同。 以Date類為例,Date類的構造器名為Date。構造一個Date對象,需要在構造器前面加上new操作符。 new Date() 這個表達式構造一個新對象,這個對象被初始化啊為當前的日期和時間。 為了讓構造的對象能多次使用,將對象存放在一個變量 Date birthday = new Date()
下圖顯示了引用新構造的對象變量birthday
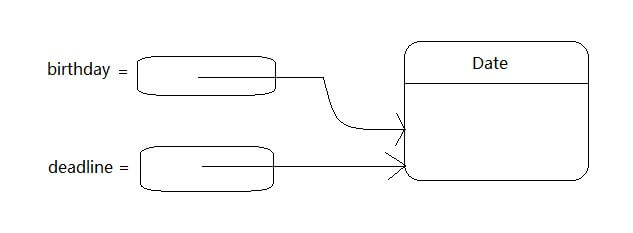
在對象與對象變量之間存在一個重要的區別。例如 Date deadline //deadline doesn’t refer to any object 定義了一個對象變量deadline,它可以引用Date類型的對象。 但是,變量deadline不是一個對象,實際上也沒有引用對象。
必須初始化變量deadline,有兩個選擇。一是用新構造的對象初始化這個變量 deadline = new Date() 二是讓這個變量引用一個已存在的對象: deadline = birthday 現在兩個變量引用同一個對象
publicstaticvoidmain(String[] args) { // TODO Auto-generated method stub
Scannerin=newScanner(System.in); System.out.print("what is your name :"); Stringname= in.nextLine(); System.out.print("age :"); intage= in.nextInt(); System.out.println("the name is " + name + ",the age is "+age); }
//輸入結果: //what is your name :jerry //age :24 //the name is jerry,the age is 24
格式化輸出
System.out.print(X)會將以x對應的數據類型所允許的最大非0數字位數打印輸出x
1 2
doublex=10000.0/3.0; System.out.print(x); // x = 3333.3333333333335
publicstaticvoidmain(String[] args) { // TODO Auto-generated method stub //抽獎遊戲,設置總數n和抽取的數k,隨機抽取 Scannerin=newScanner(System.in); System.out.println("how many numbers do you need to draw?"); intk= in.nextInt(); System.out.println("what is the highest number you can draw?"); intn= in.nextInt();
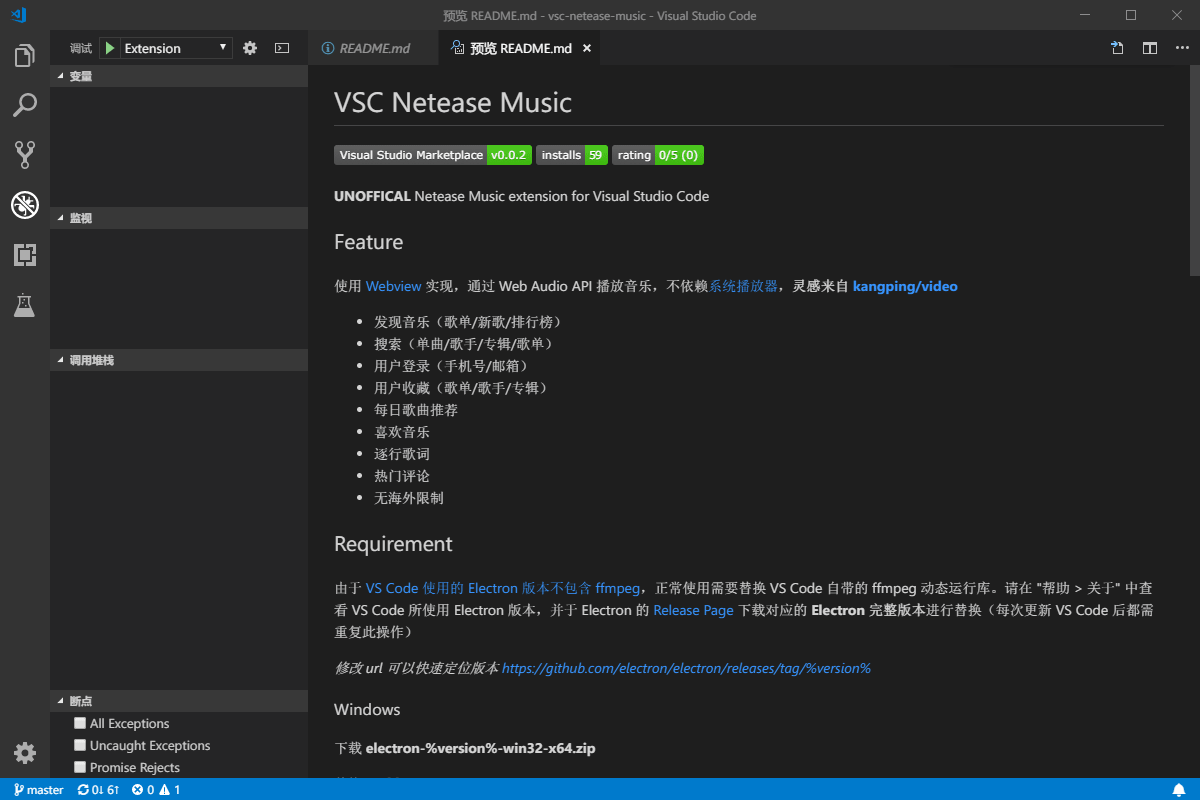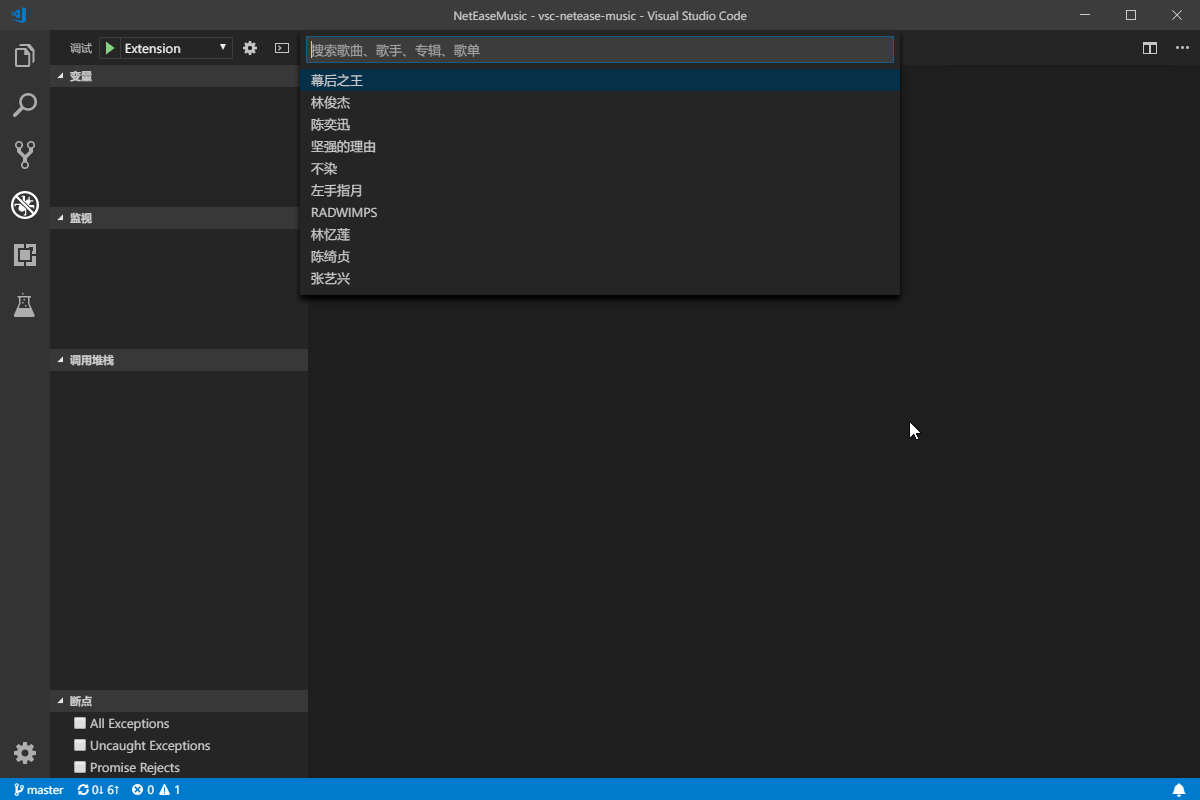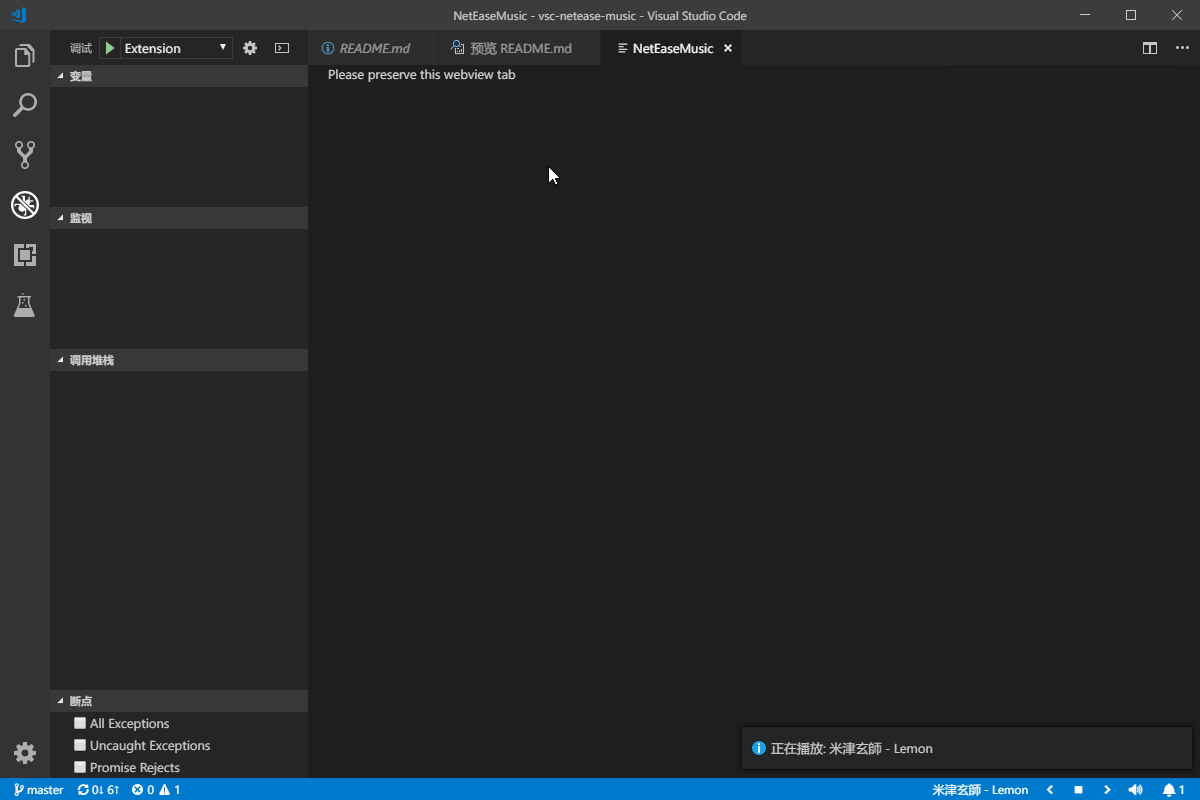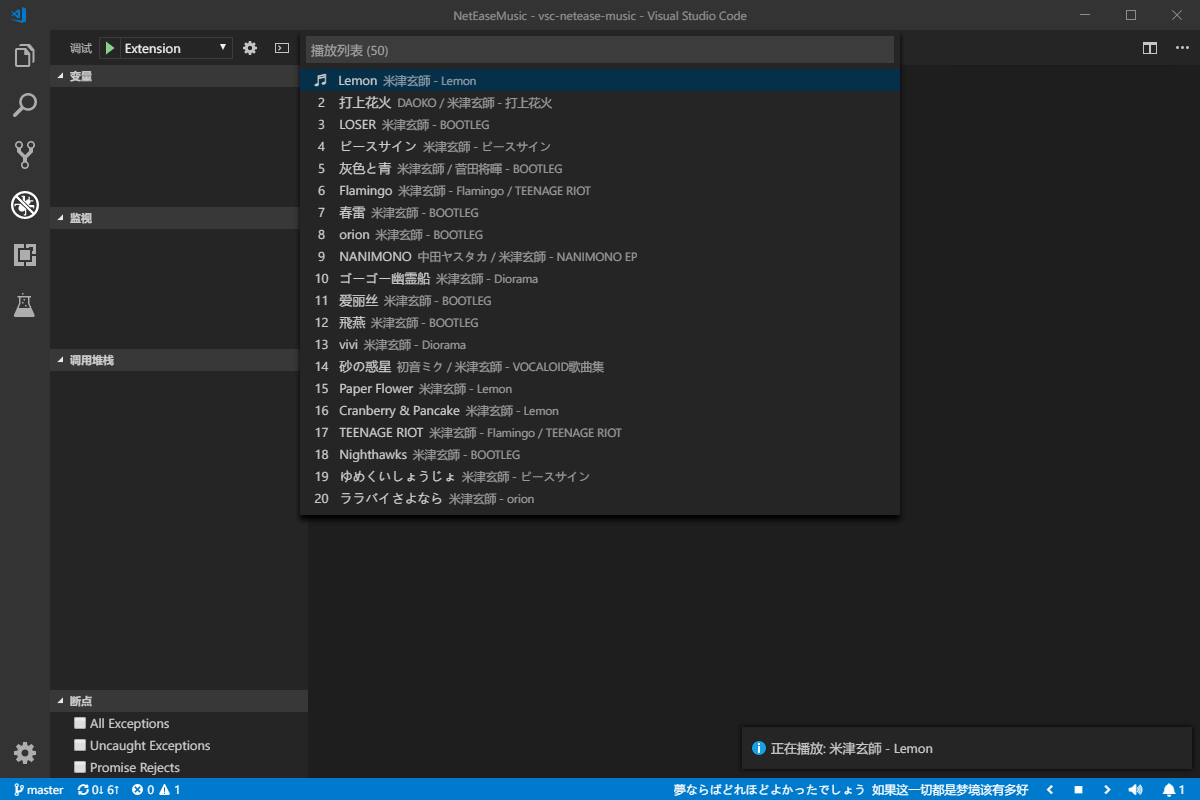
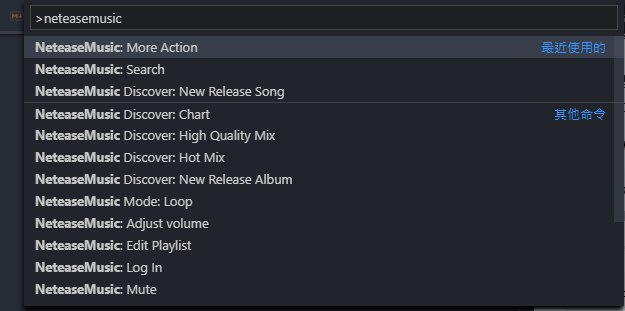
]]>對學習java的一些知識筆記Visual Studio Code 插件推薦-VSC Netease Musichttps://blog.crazywong.com/posts/86e73295/2019-03-20T16:08:30.000Z2024-02-22T09:15:04.303Z
最近在微博上看到有一位科技博主推薦了一款Visual Studio Code插件,名字叫做 VSC Netease Music。 Visual Studio Code的插件真是越來越多樣化,看漫畫、看小説,現在連聼音樂也都有了。 這款插件對我來説最吸引的,應該就是無地區版權限制了。畢竟因為版權原因,網易雲音樂早就把我拒之門外了。
]]><p><img src="https://jsd.012700.xyz/gh/jerryc127/CDN@latest/blog/VSC_Netease_Music/1.png"></p>
<p>最近在微博上看到有一位科技博主推薦了一款Visual Studio Code插件,名重裝系統後重新部署恢復 Hexo bloghttps://blog.crazywong.com/posts/dda8c81b/2018-10-14T14:05:07.000Z2024-02-22T09:15:04.303Z
以下方法只適用於沒有刪除 hexo blog 文件夾
因為重裝系統後,Hexo 相關依賴插件/軟件和在 C 盤的緩存資料都會被刪除,以至於 Hexo 的相關命令都無法運行。所有,在重裝系統後,都要重新部署 Hexo。但是重新部署並不難,只需要幾個步驟就行。 因為我的 hexo blog 文件夾不存儲於 C 盤,並沒有因為重裝系統被刪掉。所有重新部署很容易。
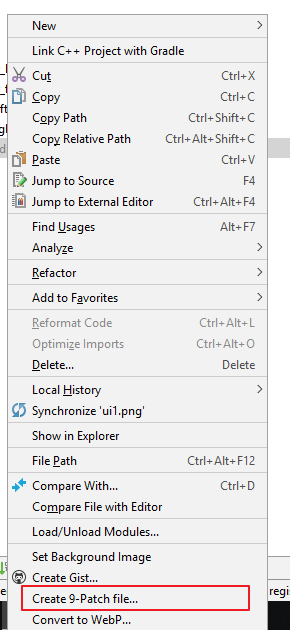
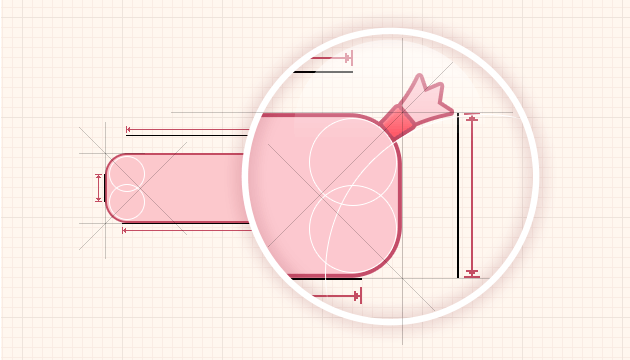
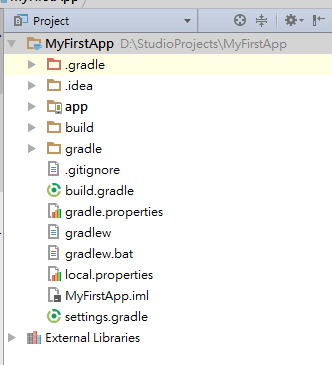
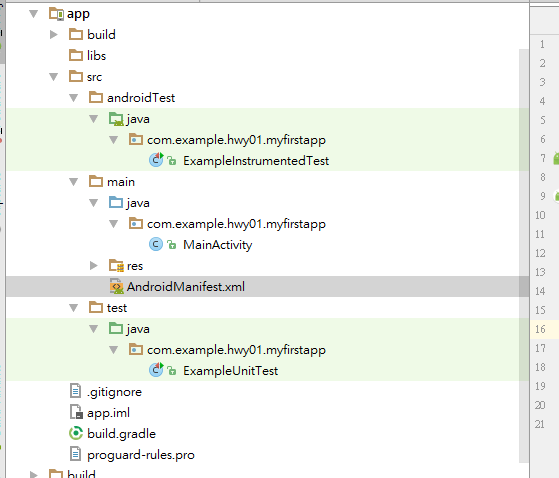
在Android Studio 上編輯.9.png,具體是在Android Studio上右鍵點擊你要編輯的照片,選擇Create 9-Patch file就可以進入編輯界面。
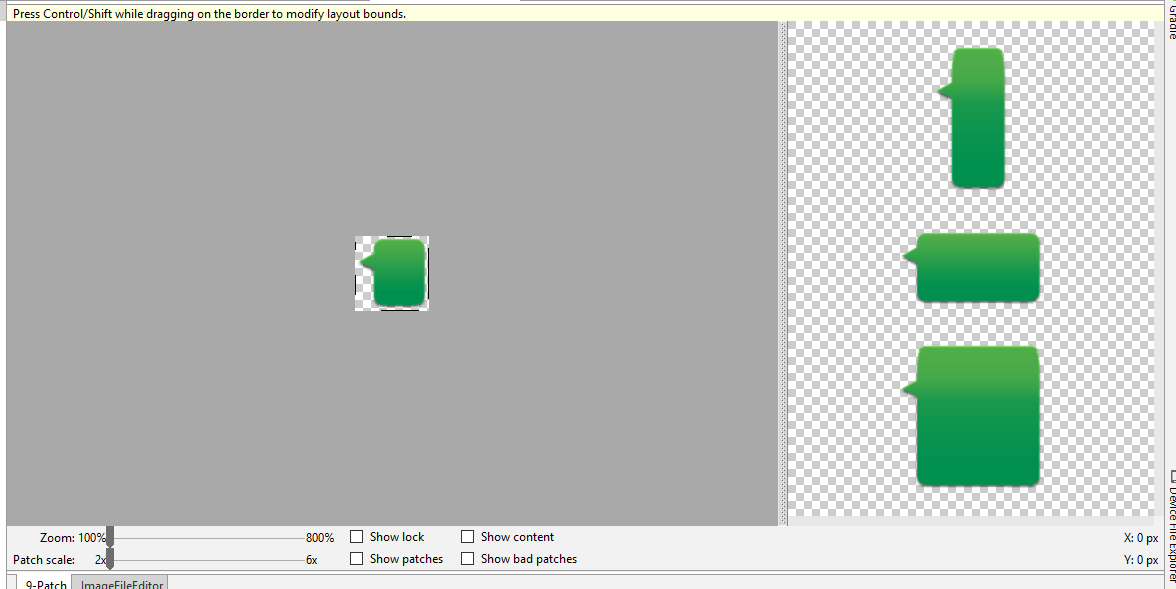
這就是9-Patch的編輯界面
Optional controls include:
Zoom: Adjust the zoom level of the graphic in the drawing area.
Patch scale: Adjust the scale of the images in the preview area.
Show lock: Visualize the non-drawable area of the graphic on mouse-over.
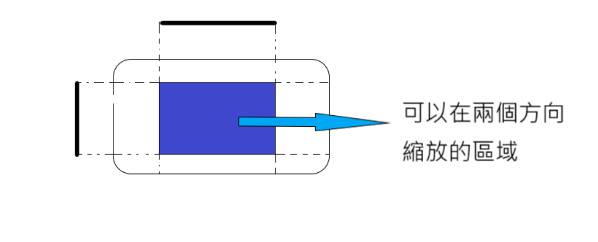
Show patches: Preview the stretchable patches in the drawing area (pink is a stretchable patch), as shown in figure 2, above.
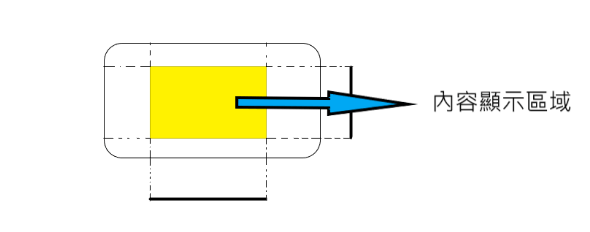
Show content: Highlight the content area in the preview images (purple is the area in which content is allowed), as shown in figure 2.
Show bad patches: Adds a red border around patch areas that may produce artifacts in the graphic when stretched, as shown in figure 2. Visual coherence of your stretched image will be maintained if you eliminate all bad patches.
While I was working on my first Android app, I found 9-patch (aka 9.png) to be confusing and poorly documented. After a little while, I finally picked up on how it works and decided to throw together something to help others figure it out.
Basically, 9-patch uses png transparency to do an advanced form of 9-slice or scale9. The guides are straight, 1-pixel black lines drawn on the edge of your image that define the scaling and fill of your image. By naming your image file name.9.png, Android will recognize the 9.png format and use the black guides to scale and fill your bitmaps.
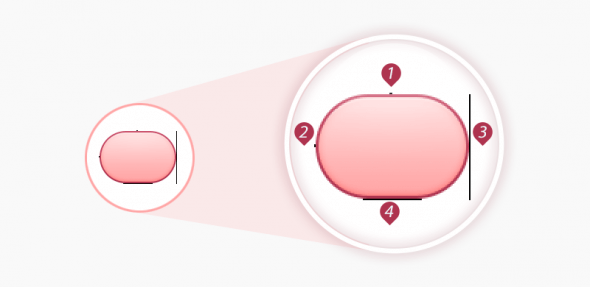
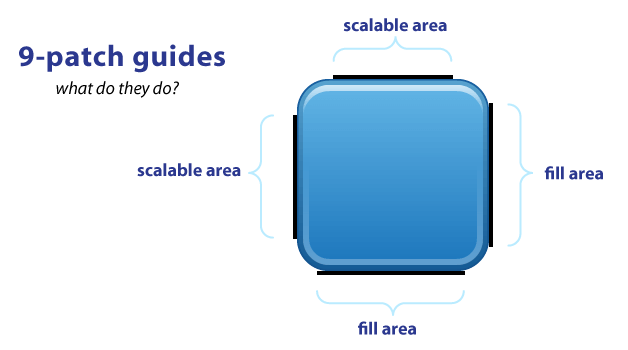
Here’s a basic guide map:
9-patch-guides
As you can see, you have guides on each side of your image. The TOP and LEFT guides are for scaling your image (i.e. 9-slice), while the RIGHT and BOTTOM guides define the fill area.
The black guide lines are cut-off/removed from your image - they won’t show in the app. Guides must only be one pixel wide, so if you want a 48x48 button, your png will actually be 50x50. Anything thicker than one pixel will remain part of your image. (My examples have 4-pixel wide guides for better visibility. They should really be only 1-pixel).
Your guides must be solid black (#000000). Even a slight difference in color (#000001) or alpha will cause it to fail and stretch normally. This failure won’t be obvious either*, it fails silently! Yes. Really. Now you know.
Also you should keep in mind that remaining area of the one-pixel outline must be completely transparent. This includes the four corners of the image - those should always be clear. This can be a bigger problem than you realize. For example, if you scale an image in Photoshop it will add anti-aliased pixels which may include almost-invisible pixels which will also cause it to fail*. If you must scale in Photoshop, use the Nearest Neighbor setting in the Resample Image pulldown menu (at the bottom of the Image Size pop-up menu) to keep sharp edges on your guides.
This is actually a “fix” in the latest dev kit. Previously it would manifest itself as all of your other images and resources suddenly breaking, not the actually broken 9-patch image.
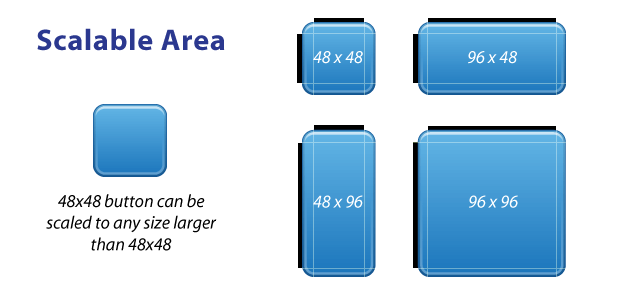
scalable-area
The TOP and LEFT guides are used to define the scalable portion of your image - LEFT for scaling height, TOP for scaling width. Using a button image as an example, this means the button can stretch horizontally and vertically within the black portion and everything else, such as the corners, will remain the same size. The allows you to have buttons that can scale to any size and maintain a uniform look.
It’s important to note that 9-patch images don’t scale down - they only scale up. So it’s best to start as small as possible.
Also, you can leave out portions in the middle of the scale line. So for example, if you have a button with a sharp glossy edge across the middle, you can leave out a few pixels in the middle of the LEFT guide. The center horizontal axis of your image won’t scale, just the parts above and below it, so your sharp gloss won’t get anti-aliased or fuzzy.
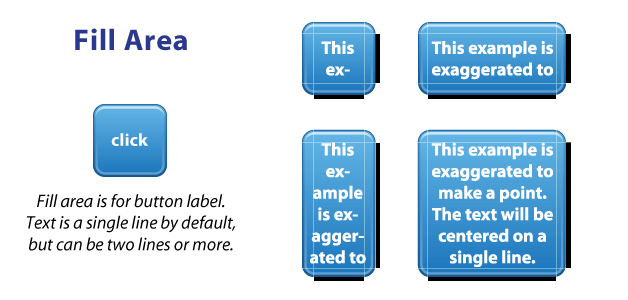
Fill area guides are optional and provide a way define the area for stuff like your text label. Fill determines how much room there is within your image to place text, or an icon, or other things. 9-patch isn’t just for buttons, it works for background images as well.
The above button & label example is exaggerated simply to explain the idea of fill - the label isn’t completely accurate. To be honest, I haven’t experienced how Android does multi-line labels since a button label is usually a single row of text.
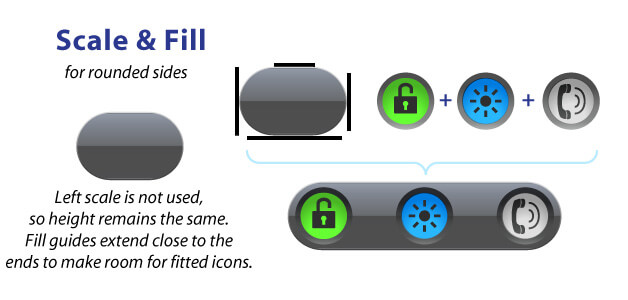
Finally, here’s a good demonstration of how scale and fill guides can vary, such as a LinearLayout with a background image & fully rounded sides:
With this example, the LEFT guide isn’t used but we’re still required to have a guide. The background image don’t scale vertically; it just scales horizontally (based on the TOP guide). Looking at the fill guides, the RIGHT and BOTTOM guides extend beyond where they meet the image’s curved edges. This allows me to place my round buttons close to the edges of the background for a tight, fitted look.
So that’s it. 9-patch is super easy, once you get it. It’s not a perfect way to do scaling, but the fill-area and multi-line scale-guides does offer more flexibility than traditional 9-slice and scale9. Give it a try and you’ll figure it out quickly.
# Post wordcount display settings # Dependencies: https://github.com/theme-next/hexo-symbols-count-time symbols_count_time: separated_meta:true #文章中的顯示是否顯示文字(本文字數|閱讀時長) item_text_post:true #網頁底部的顯示是否顯示文字(站點總字數|站點閱讀時長) item_text_total:false # Average Word Length (chars count in word) awl:4 # Words Per Minute wpm:275
footer: since:2018 # Icon between year and copyright info. icon: name:user animated:false color:"#808080" powered: # Hexo link (Powered by Hexo). enable:true # Version info of Hexo after Hexo link (vX.X.X). version:true theme: # Theme & scheme info link (Theme - NexT.scheme). enable:false # Version info of NexT after scheme info (vX.X.X). version:false
<span id="sitetime"></span> <script language=javascript> function siteTime(){ window.setTimeout("siteTime()", 1000); var seconds = 1000; var minutes = seconds * 60; var hours = minutes * 60; var days = hours * 24; var years = days * 365; var today = new Date(); var todayYear = today.getFullYear(); var todayMonth = today.getMonth()+1; var todayDate = today.getDate(); var todayHour = today.getHours(); var todayMinute = today.getMinutes(); var todaySecond = today.getSeconds(); var t1 = Date.UTC(2018,06,07,12,00,00); // 設置建立網站的時間 var t2 = Date.UTC(todayYear,todayMonth,todayDate,todayHour,todayMinute,todaySecond); var diff = t2-t1; var diffYears = Math.floor(diff/years); var diffDays = Math.floor((diff/days)-diffYears*365); var diffHours = Math.floor((diff-(diffYears*365+diffDays)*days)/hours); var diffMinutes = Math.floor((diff-(diffYears*365+diffDays)*days-diffHours*hours)/minutes); var diffSeconds = Math.floor((diff-(diffYears*365+diffDays)*days-diffHours*hours-diffMinutes*minutes)/seconds); document.getElementById("sitetime").innerHTML=" 已運行"+diffYears+" 年 "diffDays+" 天 "+diffHours+" 小時 "+diffMinutes+" 分鐘 "+diffSeconds+" 秒"; } siteTime(); </script>

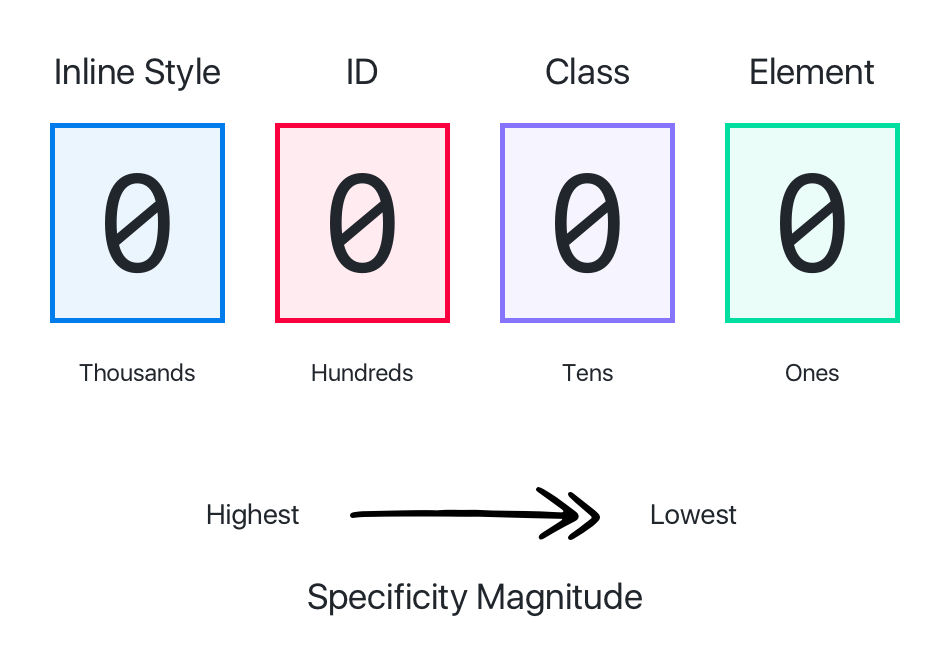
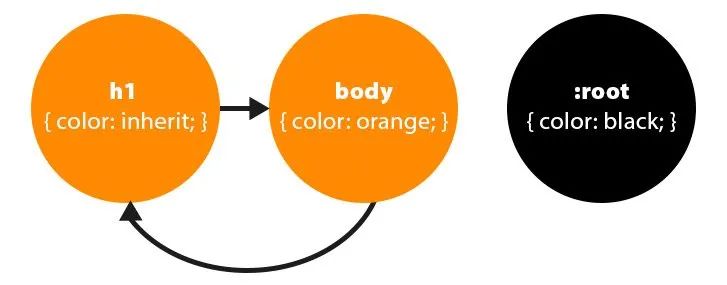
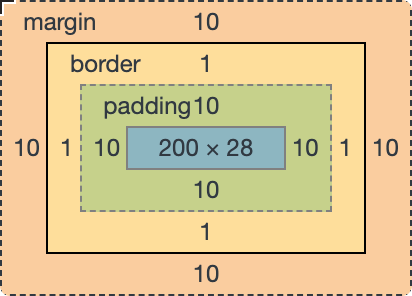
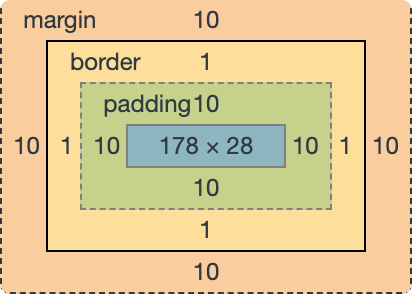
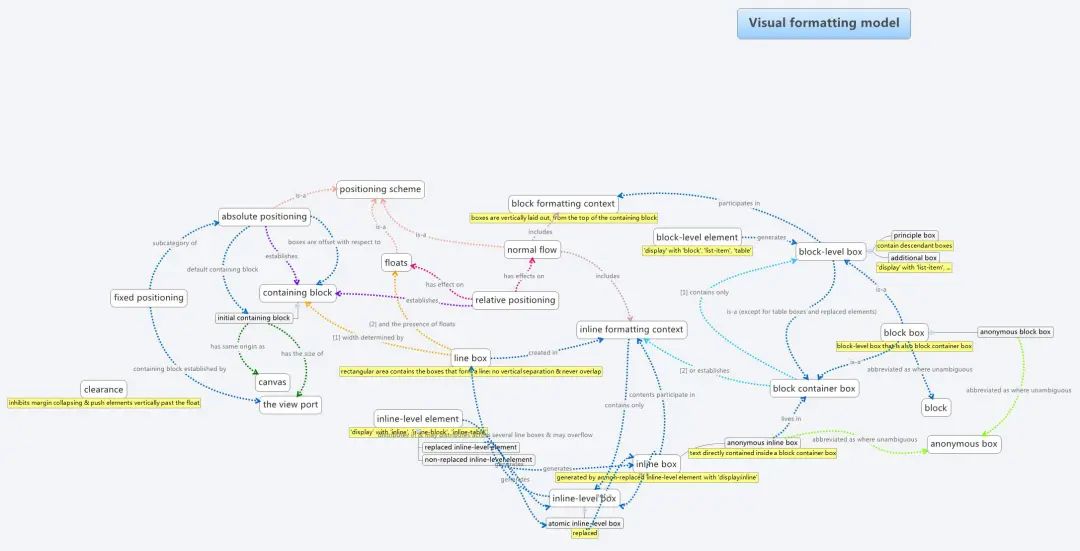

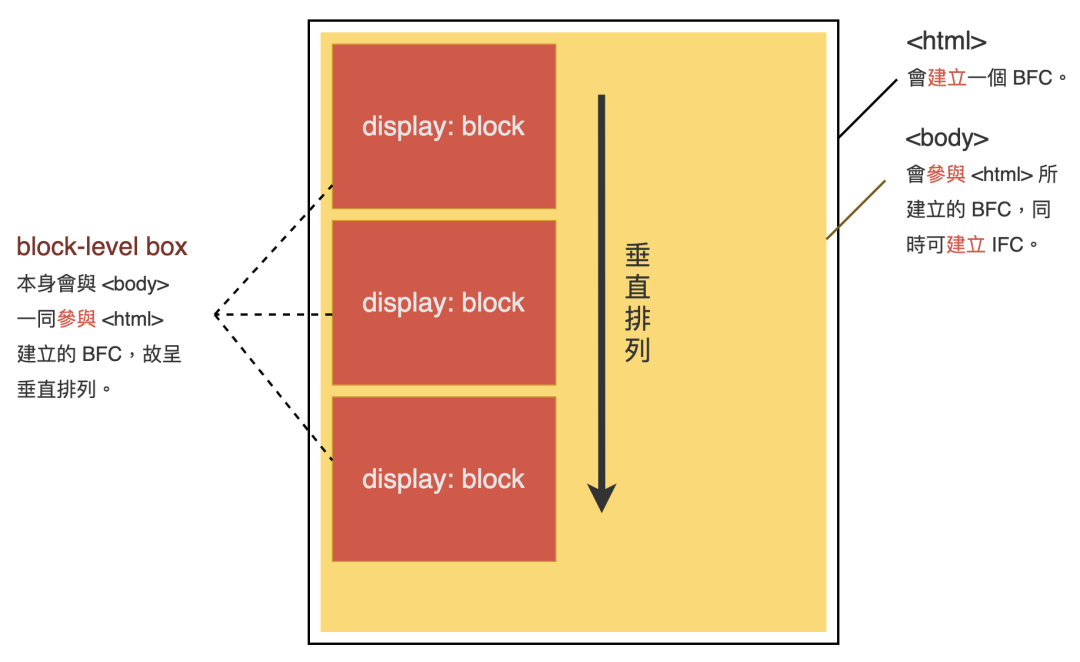



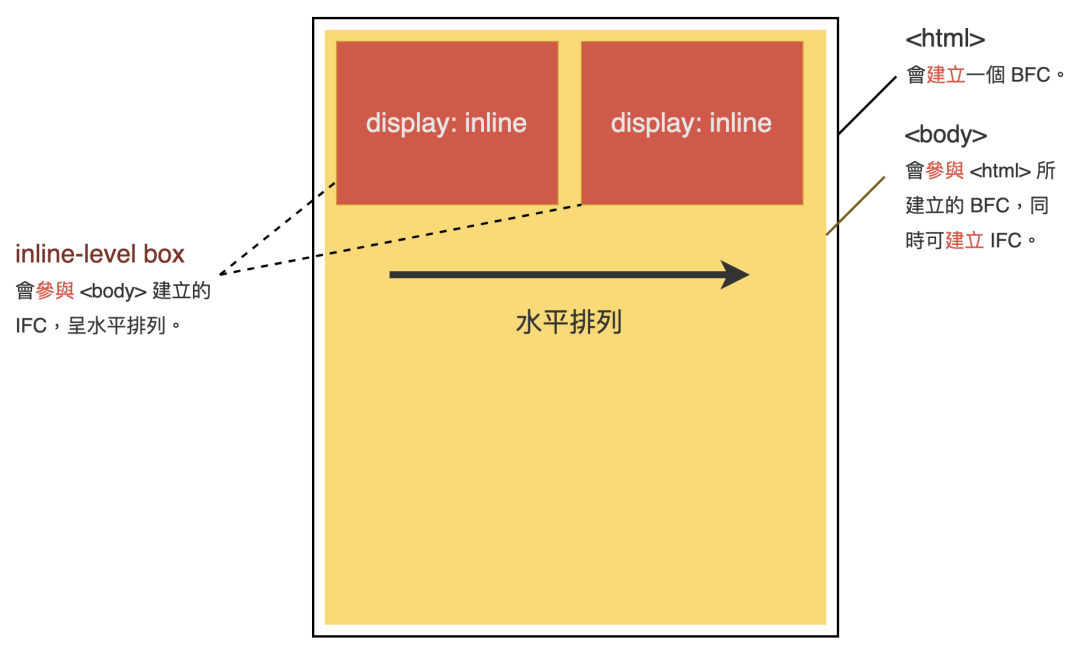
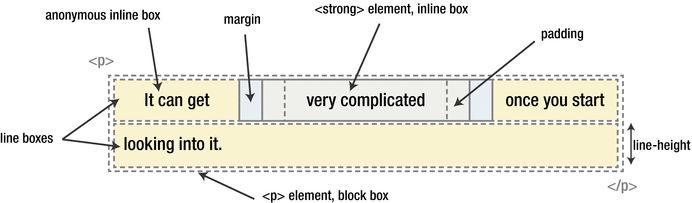









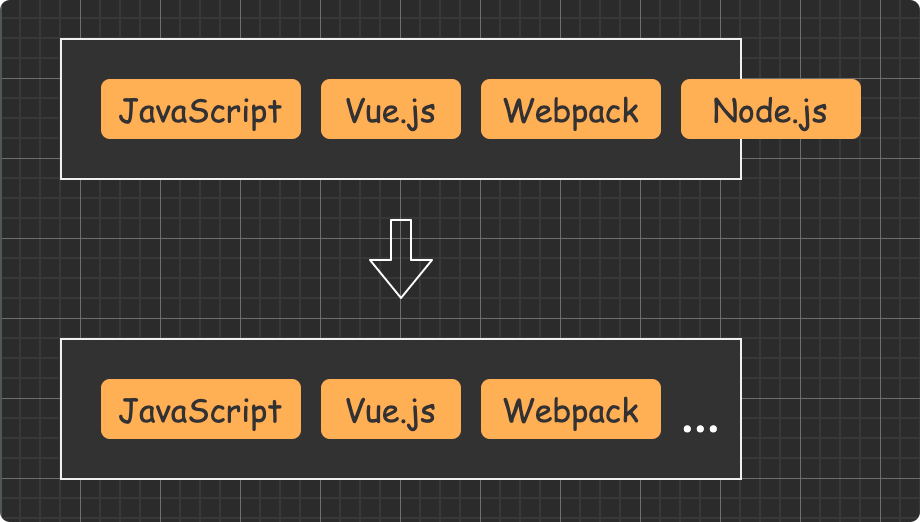

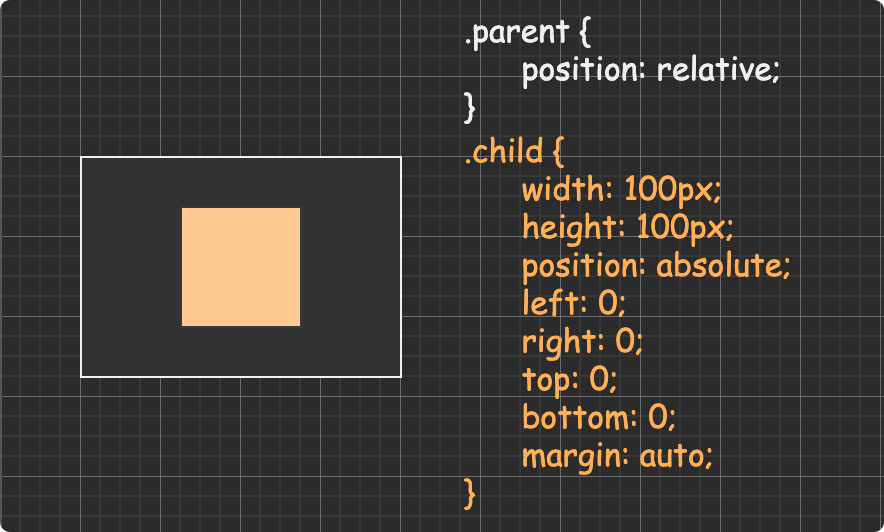


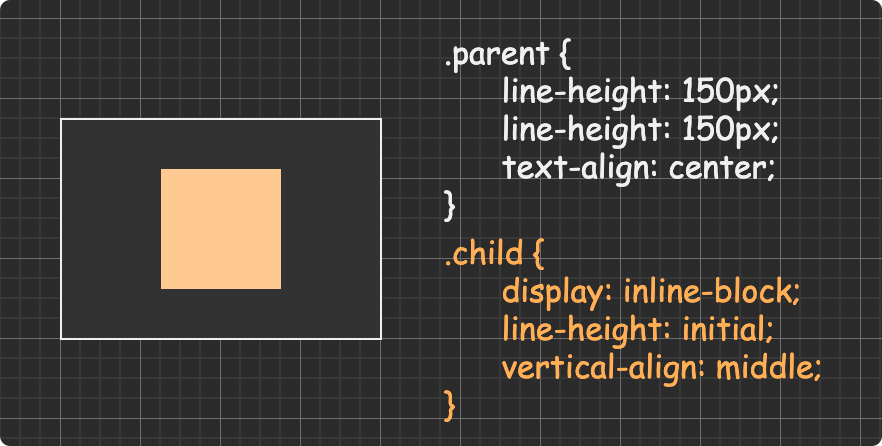
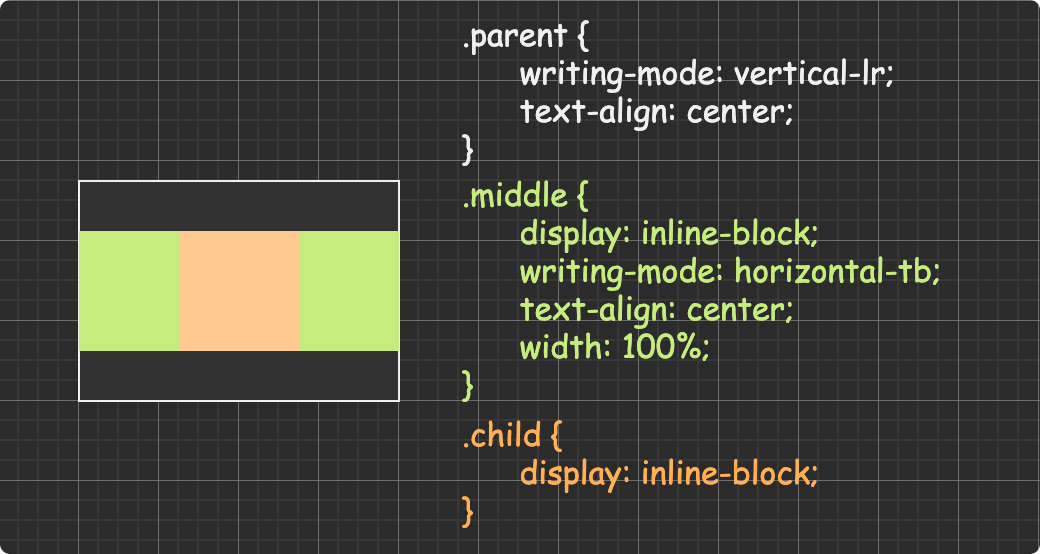




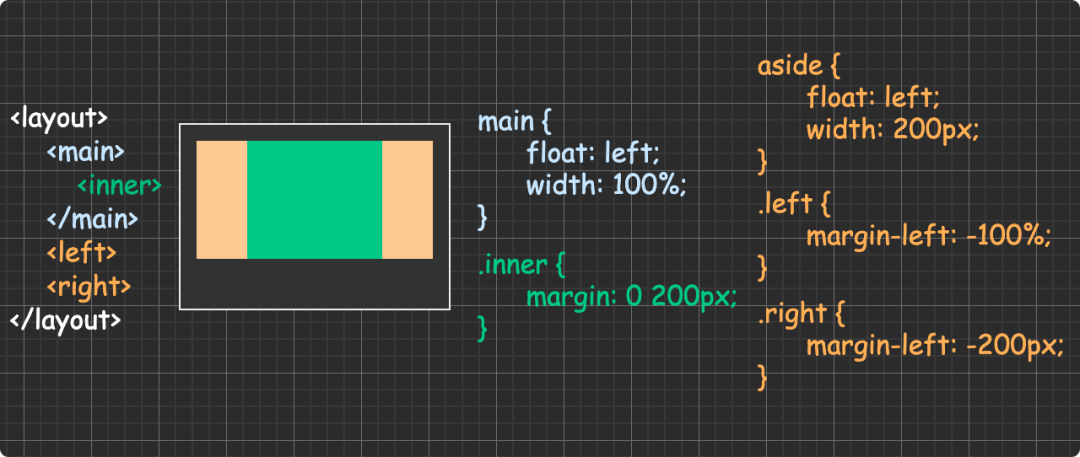
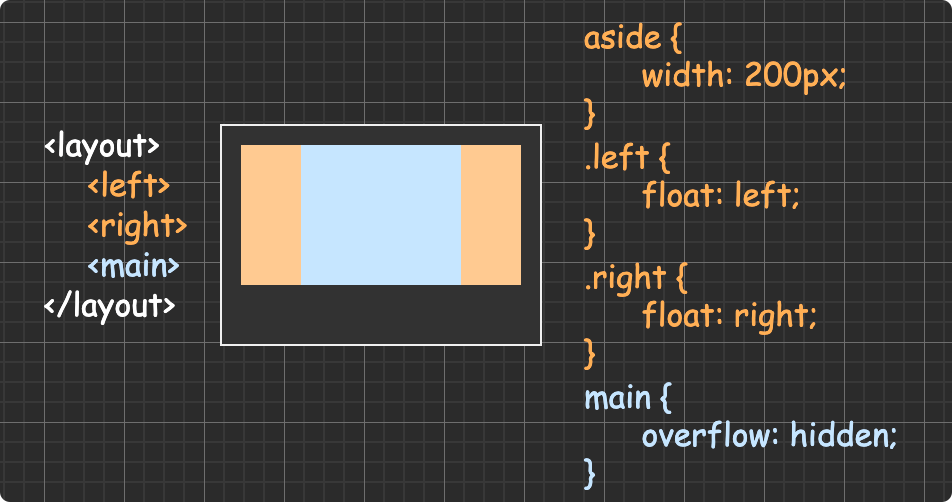
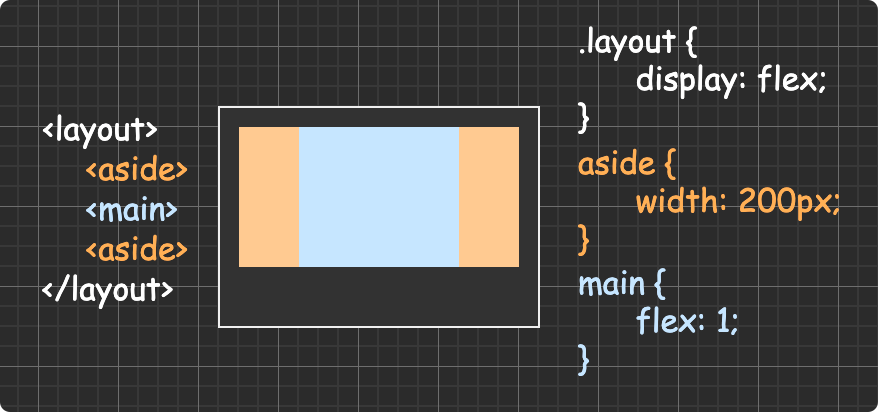
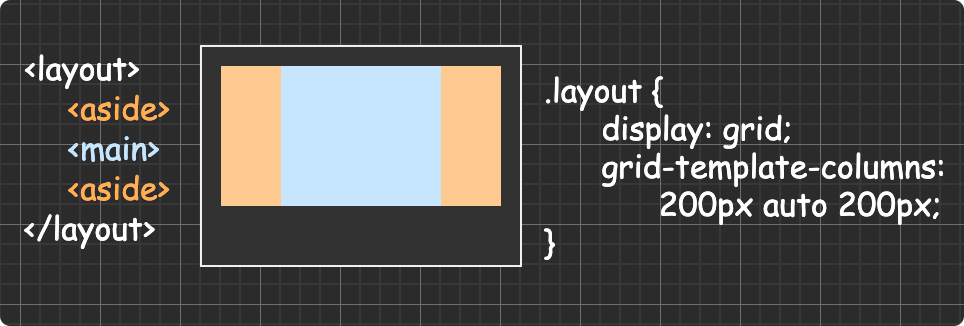



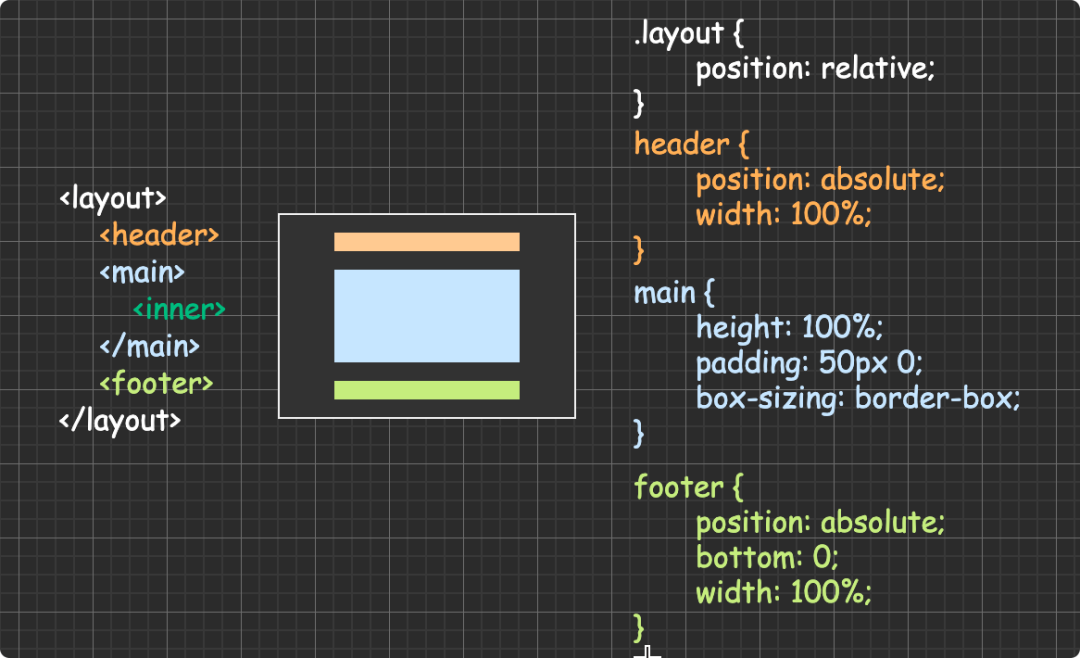
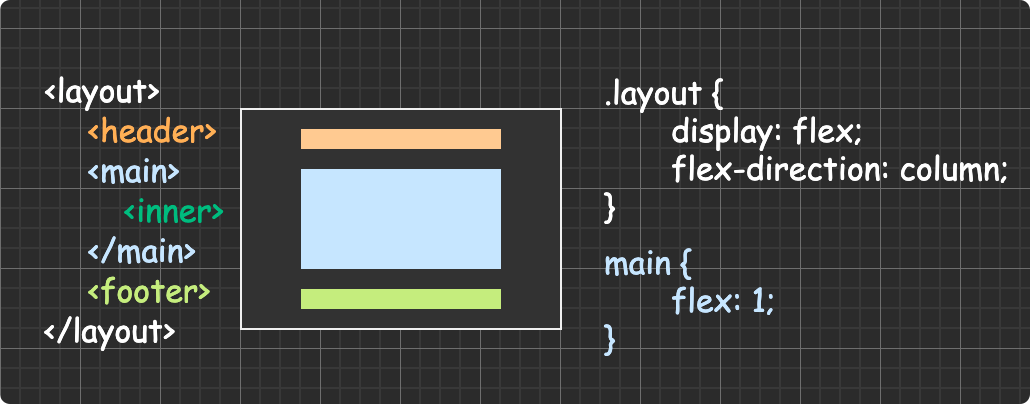
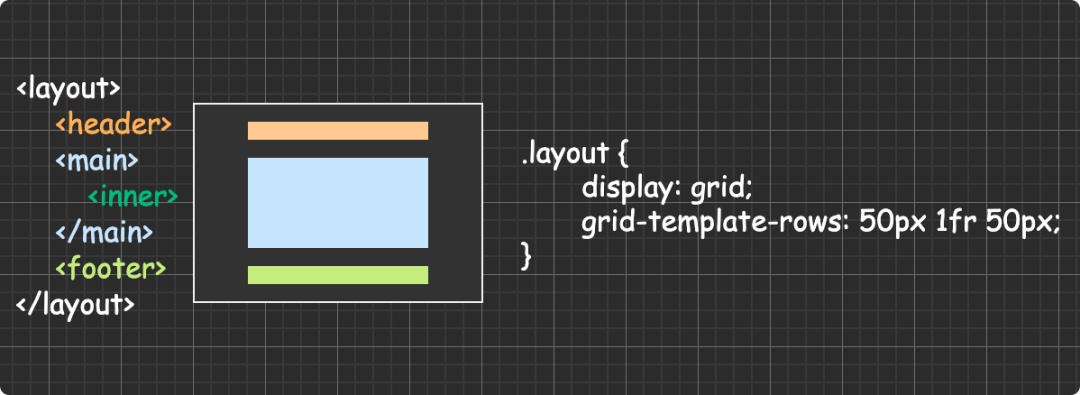

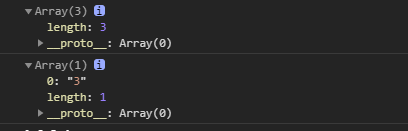


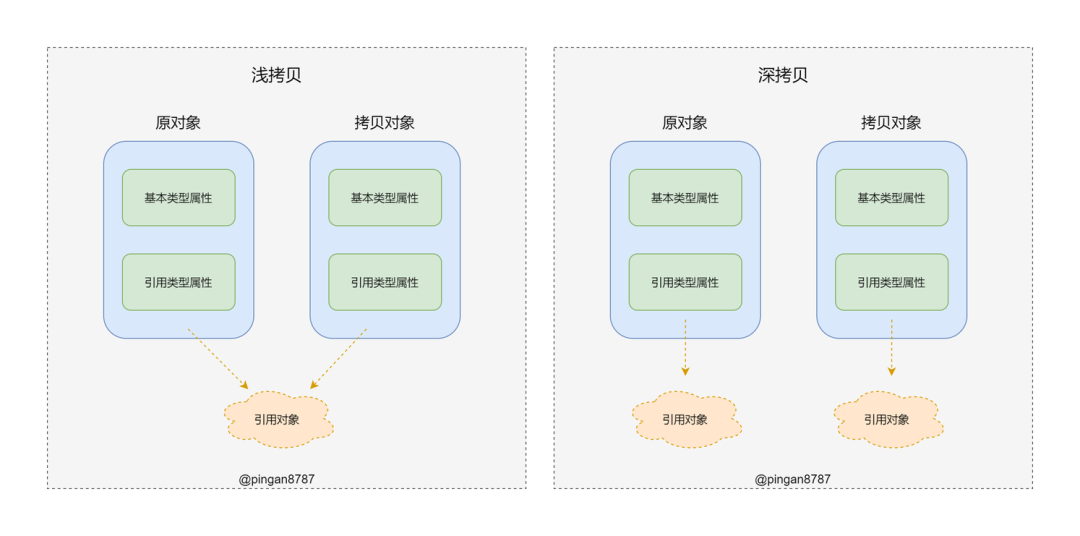


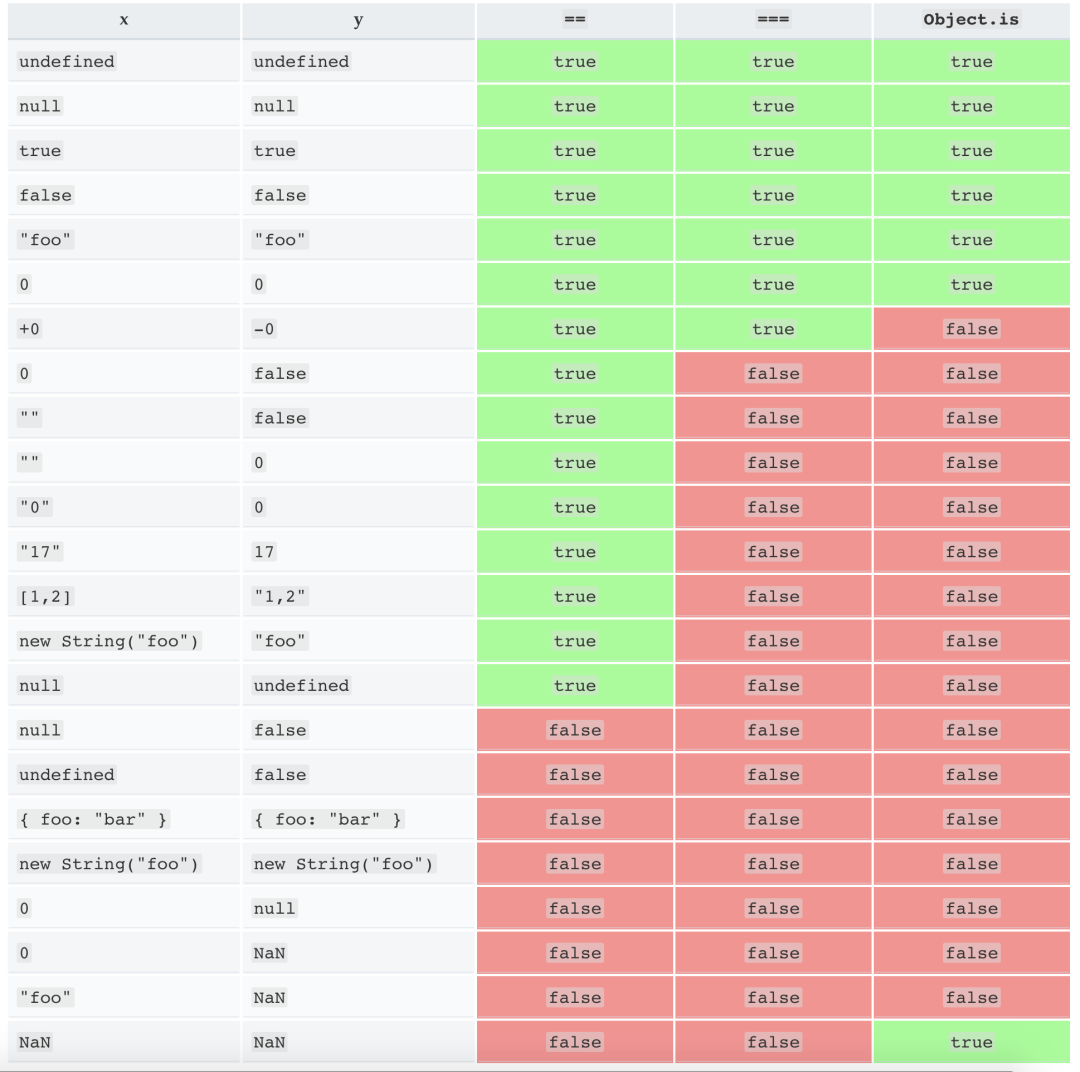 (圖片來自:《MDN JavaScript 中的相等性判斷》)
(圖片來自:《MDN JavaScript 中的相等性判斷》)